El pasado 11 de diciembre he participado en la VII Jornada Profesional de la Red de Bibliotecas del Instituto Cervantes «Big data y bibliotecas: convertir datos en conocimiento» con una ponencia titulada «La curación de contenidos en la era de la infoxicación. Propuestas para bibliotecas«. Mi participación ha sido en el segundo panel, titulado Caos en el orden, moderado por Victor Arbe , junto a Jorge Serrano Cobos, Ricardo Alonso Maturana y Ana Lorente. La sesión ha sido bastante seguida en las redes sociales (hashtag #VIIjornadaRBIC).

De i a d: Arbe, Guallar, Lorente, Alonso Maturana y Serrano Cobos (foto: Ciro LLueca)
En unas jornadas dedicadas al big data y a su aplicación en el sector de las bibliotecas, me ha tocado defender y argumentar el punto de vista de la content curation, que en este contexto se puede entender como otro modelo que, como el big data, parte del problema del gran volumen de información existente para plantear soluciones al mismo.
Mi presentación constó de tres partes: Origen y situación actual de la content curation; Content curation vs. big data; Propuestas para bibliotecas.
De los temas que trato en la primera y la tercera parte venimos hablando habitualmente en este blog, por lo que aprovecharé este post para desarrollar los argumentos de la parte central, es decir, la que trata la relación entre los conceptos de content curation y big data.
En común
Empezando por lo que tienen en común, ambos son sistemas o modelos de filtrado de información que se presentan como soluciones ante la realidad inapelable de la ingente cantidad de contenidos/datos existente y en continuo aumento. Y ambos modelos han surgido muy recientemente: Ana Lorente ha comentado que la figura del data scientific o científico de datos – la profesión más directamente relacionada con big data- no existía hace cinco años; con el content curator sucede lo mismo.
Diferencias
Tras los puntos en común, he desgranado tres grupos de diferencias:

Sistemas automatizados vs. sistemas manuales
 La primera de ellas es sin duda la principal diferencia entre ambos conceptos. La CC surge (Manifiesto de Bhargava) como una solución “manual” o “humana” y de reacción frente a los “algoritmos”, a los cuales se señala como incapaces por si solos de satisfacer las necesidades de información de las personas. Este planteamiento de situar el “criterio humano” en el eje de la curation es sin duda básico para comprender adecuadamente el enfoque de la CC. Es algo que no se puede obviar. Por eso, creo que no se deberían considerar CC algunas visiones que tienden a pasarlo por alto porque automatizan al máximo el proceso.
La primera de ellas es sin duda la principal diferencia entre ambos conceptos. La CC surge (Manifiesto de Bhargava) como una solución “manual” o “humana” y de reacción frente a los “algoritmos”, a los cuales se señala como incapaces por si solos de satisfacer las necesidades de información de las personas. Este planteamiento de situar el “criterio humano” en el eje de la curation es sin duda básico para comprender adecuadamente el enfoque de la CC. Es algo que no se puede obviar. Por eso, creo que no se deberían considerar CC algunas visiones que tienden a pasarlo por alto porque automatizan al máximo el proceso.
Sobre ello nos extendimos loscontentcurators en el Epílogo del libro El content curator: en esa –al parecer eterna- disputa entre la prevalencia del hombre o de la máquina en la gestión de información, la CC propone poner de nuevo al frente del proceso al hombre, después de que en los primeros tiempos de la Web, el modelo de clasificación manual que representaba entonces el directorio de Yahoo fracasara frente a la potencia y precisión del modelo automatizado que representaban los algoritmos de Google. En este sentido, 15 años o 20 años después, content curation y big data se pueden ver como una nueva fase de esa diferente perspectiva –humana o algorítmica– frente al problema del acceso a la información.
En los momentos actuales de la CC, cinco años después de su nacimiento con el Manifiesto de Bhargava, parece necesario no obstante, sin desdecirme del punto anterior, matizarlo: no se niega la prevalencia del criterio humano en la CC, pero ello no significa que el proceso de curation deba ser forzosamente artesanal (aunque también esta sea una opción válida). Recuérdese la 4ª de las 5 leyes de Rosenbaum: “el content curator debe usar tecnología y herramientas en su proceso de curation”. Es en este punto en el que se puede entender y situar la posible relación entre big data y content curation.
Conjuntos y subconjuntos
La relación entre big data y content curation, se puede entender al menos desde dos perspectivas o puntos de vista. Por una parte, se puede ver el big data como un conjunto de tecnologías y de sistemas que se pueden aplicar a diversidad de enfoques, y uno de estos subconjuntos de aplicación puede ser la content curation. Abunda en esta visión el hecho de que en cuanto a materia prima, el big data abarca en principio un conjunto mayor de tipos de informaciones que la CC (por ejemplo, datos estructurados y no estructurados: la V de «variedad», una de las famosas V del big data). Esta sería la visión de los especialistas en big data.

Pero desde el punto de vista de la CC, se puede plantear también la anterior representación gráfica justamente al revés; es decir, la relación entre ambos sistemas se puede entender como la posibilidad de utilización de tecnologías big data dentro de una estrategia o metodología de CC.

Las 4 S’s, en modelos más o menos automatizados
Si aplicamos esta última idea en un método de CC, por ejemplo el de las 4S’s, se pueden distinguir dos modelos. Por una parte, en el que podemos denominar modelo «clásico» de CC, de las 4S’s (Search, Select, Sense making, Share), habría dos fases más claramente automatizables, que son la primera y la cuarta: Search y Share, y dos que son fundamentalmente manuales, donde el criterio del curator es esencial: las fases segunda y tercera: Select y Sense Making. Esto es, en líneas generales, lo que planteamos en nuestro libro El content curator.

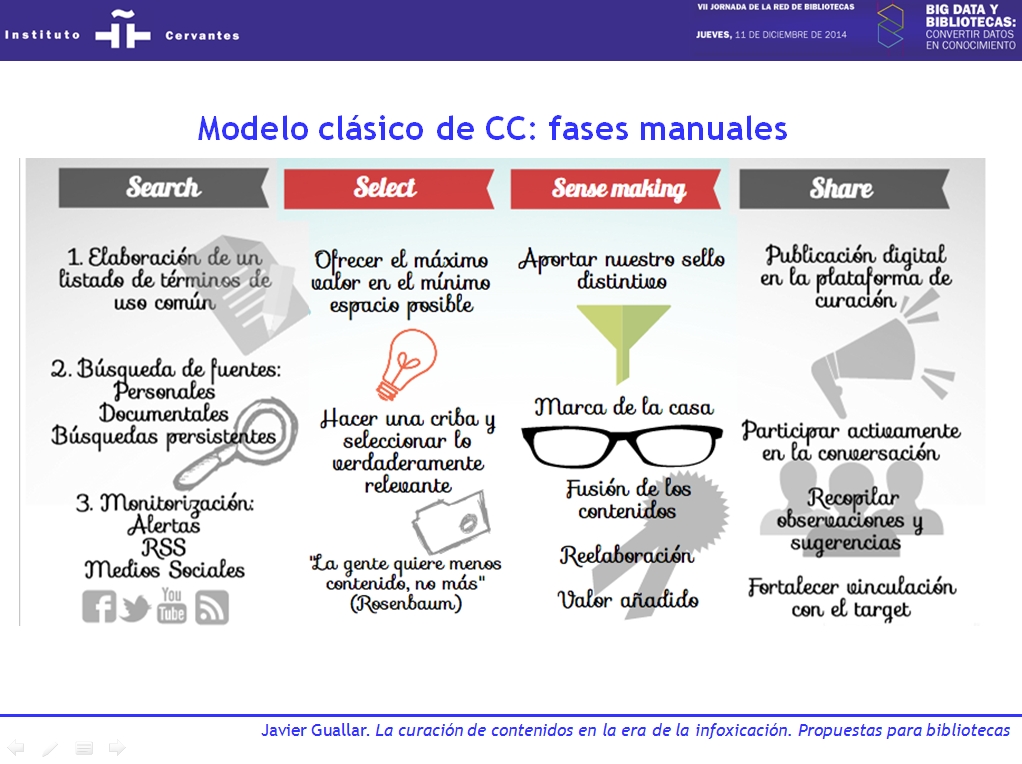
Pero si aplicamos las 4S’s en un escenario con alta utilización de tecnologías, por ejemplo, de uso de tecnologías big data, podemos considerar que el empleo de sistemas automatizados se puede extender también a la fase de selección de contenidos (Select). Quedaría así por tanto el que podemos denominar modelo «CC + big data», en el cual las fases de Search, Select y Share se pueden automatizar en gran medida, y solamente habría una fase mayoritariamente manual, la de Sense making o caracterización de contenidos.
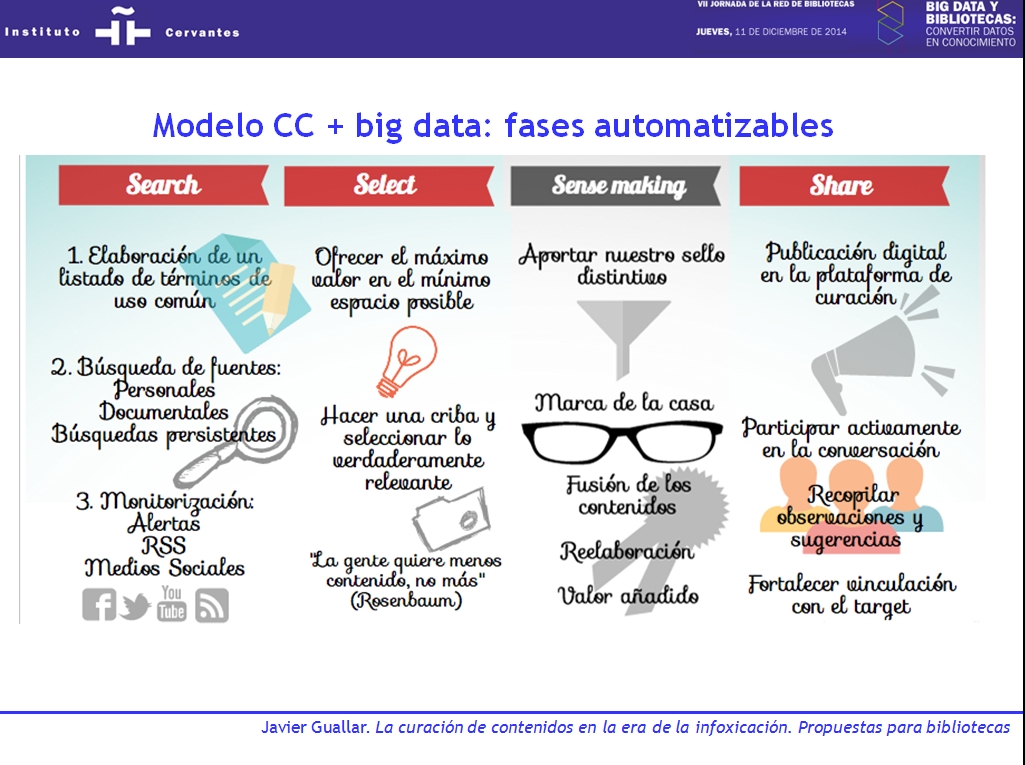

A partir de los modelos anteriores, la combinación entre la automatización y el trabajo manual, intelectual o artesanal puede ser diversa, a nivel global y dentro de cada fase del proceso de CC; pero si bien, en un extremo, sí se puede hablar de una CC muy «artesanal», no creo que se pueda hablar de CC si es excesivamente automatizada.
En cualquier caso, seguramente el futuro de la curation, como ha señalado recientemente Rosenbaum, se encuentra en la sabia combinación de criterio humano y algoritmos.
Relacionado:
Ciro Llueca en Blog EPI: Crónica de la VII Jornada Profesional de la RBIC “big data y bibliotecas: convertir datos en conocimiento”
Vídeos sobre curación de contenidos, big data y bibliotecas
About Javier Guallar
Profesor de Documentación y Comunicación, Editor, y Content Curator. En UB, revista Profesional de la información (EPI), libros Profesional de la información y EPI Scholar (Ed.UOC), Los content curators. Coautor libros "El content curator", "Las 4S's de la content curation", "Calidad en sitios web", "Prensa digital y bibliotecas". Mi newsletter: https://www.getrevue.co/profile/jguallar
Pingback: El profesional de la información » Blog Archive » Crónica de la VII Jornada Profesional de la RBIC “big data y bibliotecas: convertir datos en conocimiento”
Pingback: Vídeos sobre curación de contenidos, big data y bibliotecas | Los Content Curators